Node Pool 로 KubernetesPodOperator 를 위한 독립된 실행 환경 구성하기
Cloud Composer 를 써보기 위해 Environment 를 만들 때, Worker nodes 의 Node count 와 Machine type 값을 어떻게 줄 지 고민했습니다. 넉넉한 걸로 하자니 비용이 아까웠고, 작은 걸로 하자니 이후 resource 가 많이 필요한 task 를 실행할 수도 있을 것 같아 망설여집니다. Environment 생성 후에 Machine type 을 바꾸려면 Upgrading the machine type 문서에서 소개하는, default-pool 을 없애고 새로 만드는 방법을 써야 하는데, 그 동안 task 실행이 중단되는 것도 그렇고 그리 매력적이지 않습니다. Upgrading the machine type 문서에서도 처음 Environment 를 생성할 때 machine type 을 잘 선택하고, resource 가 많이 필요한 task 를 실행하고 싶으면 GKEPodOperator 를 쓰라고 얘기합니다.
We recommend you specify the ideal machine type for the type of computing that will occur in your Cloud Composer environment when you create an environment. If you are running jobs that perform heavyweight computation, first try the GKEPodOperator.
그래서 Using the KubernetesPodOperator 문서를 참고하여, Environment 와 독립적이고 가변적인 resource 를 별도로 관리하며 task 를 실행하는 방법을 알아봤습니다. 참고로 KubernetesPodOperator 는 GKEPodOperator 의 super class 입니다. GKEPodOperator 는 임의의 GKE Cluster 에 pod 을 띄우는 상황을 가정하여 기능을 확장한 class 인데, Environment 와 GKE Cluster 는 공유할 것이므로, 기본이 되는 (또한 문서에서 소개하는) KubernetesPodOperator 를 써봅니다.
Node Pool 생성
Node pools 문서의 Overview 에 따르면, node pool 이란 같은 NodeConfig 을 공유하는 node 그룹입니다. Cluster 를 생성할 때 설정에 맞춰 default node pool 이 만들어지는데, Cloud Composer 의 Environment 를 생성할 때에도 마찬가지입니다. 그렇게 만들어진 default pool 에서, Airflow 를 구성하는 Kubernetes Object 들이 실행되고 있습니다. Environment 가 생성한 Kubernetes Engine Cluster 의 Workloads 탭에서 이를 확인할 수 있습니다.
A node pool is a group of nodes within a cluster that all have the same configuration. Node pools use a NodeConfig specification. Each node in the pool has a Kubernetes node label, cloud.google.com/gke-nodepool, which has the node pool’s name as its value. A node pool can contain only a single node or many nodes.
When you create a cluster, the number and type of nodes that you specify becomes the default node pool. Then, you can add additional custom node pools of different sizes and types to your cluster. All nodes in any given node pool are identical to one another.
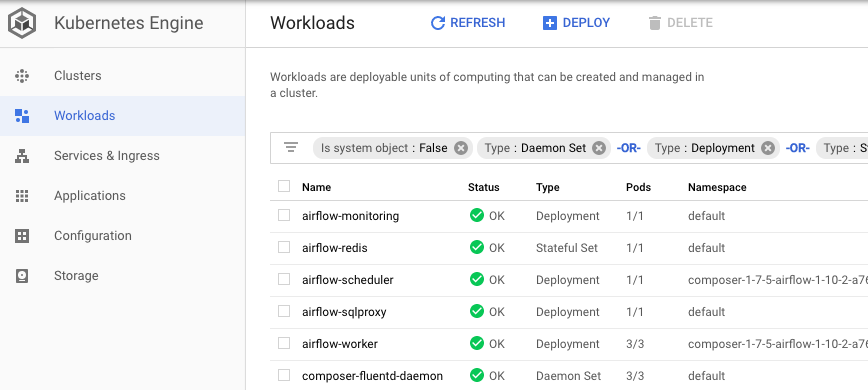
Kubernetes Engine Console 의 Clusters 탭에서 Environment 가 띄운 Cluster 를 선택하고, 상단의 ADD NODE POOL 버튼을 클릭하고 설정값을 입력해서 새로운 node pool 을 생성합니다. KubernetesPodOperator 로 실행할 Task 들을 위한 별도의 node pool 입니다.
- Name : 적당한 이름으로. 기본 값으로 채워져있는
pool-1이 마음에 드네요. - Node version : 1.12.8-gke.10 (master version)
- Number of nodes : 0
- Enable autoscaling : True (Minimum number of nodes : 0, Maximum number of nodes : 1)
- Image type : Container-Optimized OS (cos) (default)
- Machine family : General-purpose
- Generation : First (더 최신 세대인 Second 가 있지만 최소 Machine type 이 높음)
- Machine type : n1-standard-1 (1 vCPU, 3.75 GB memory)
- Book disk type : Standard persistent disk
- Book disk size (GB) : 10 (최소값)
- Local SSD disks : 0
- Enable preemptible nodes (beta) : False
- Enable auto-upgrade : True
- Enable auto-repair : True
- Service account : 적당한 권한을 지닌 service account 로 선택.
DAG 추가
Pod Affinity Configuration 문서의 코드를 참고해서 DAG 를 선언합니다. Task 실행을 위한 Pod 이 방금 만든 pool-1 node pool 에 뜰 수 있도록, affinity argument 를 넘깁니다.
from datetime import datetime, timedelta
from airflow import models
from airflow.contrib.operators.kubernetes_pod_operator import KubernetesPodOperator
with models.DAG('dag_node_pool',
schedule_interval=timedelta(minutes=1),
start_date=datetime(2019, 10, 3, 0, 0, 0),
catchup=False) as dag:
# namespace, name 은 필수.
# 잘 모르겠으니 namespace 는 'default' 로 하고, name 은 task_id 와 동일하게.
node_pool_test = KubernetesPodOperator(
task_id='node-pool-test',
namespace='default',
image='bash',
name='node-pool-test',
cmds=['echo', 'fakenerd'],
affinity={
'nodeAffinity': {
# scheduling 때 조건 확인하고, execution 중 조건 충족하지 않게 되도, pod 은 쭉 실행.
# Node Pool 만들 때 알아서 'cloud.google.com/gke-nodepool' label 이 달립니다.
'requiredDuringSchedulingIgnoredDuringExecution': {
'nodeSelectorTerms': [{
'matchExpressions': [{
'key': 'cloud.google.com/gke-nodepool',
'operator': 'In',
'values': ['pool-1']
}]
}]
}
}
}
)
DAG 를 upload 하고 기다리면, Task 가 스케줄링 되고, 잘 실행된 것을 로그를 통해 확인할 수 있습니다.
-------------------------------------------------------------------------------
Starting attempt 1 of
-------------------------------------------------------------------------------
[2019-10-06 08:53:11,687] {models.py:1599} INFO - Executing <Task(KubernetesPodOperator): node-pool-test> on 2019-10-06T08:51:02.859698+00:00
[2019-10-06 08:53:11,690] {base_task_runner.py:118} INFO - Running: ['bash', '-c', 'airflow run dag_node_pool node-pool-test 2019-10-06T08:51:02.859698+00:00 --job_id 15096 --raw -sd DAGS_FOLDER/dag_node_pool.py --cfg_path /tmp/tmppfr0nx6w']
[2019-10-06 08:53:19,466] {base_task_runner.py:101} INFO - Job 15096: Subtask node-pool-test [2019-10-06 08:53:19,463] {settings.py:176} INFO - settings.configure_orm(): Using pool settings. pool_size=5, pool_recycle=1800, pid=68219
[2019-10-06 08:53:22,159] {base_task_runner.py:101} INFO - Job 15096: Subtask node-pool-test [2019-10-06 08:53:22,158] {default_celery.py:90} WARNING - You have configured a result_backend of redis://airflow-redis-service.default.svc.cluster.local:6379/0, it is highly recommended to use an alternative result_backend (i.e. a database).
[2019-10-06 08:53:22,161] {base_task_runner.py:101} INFO - Job 15096: Subtask node-pool-test [2019-10-06 08:53:22,161] {__init__.py:51} INFO - Using executor CeleryExecutor
[2019-10-06 08:53:22,390] {base_task_runner.py:101} INFO - Job 15096: Subtask node-pool-test [2019-10-06 08:53:22,390] {app.py:52} WARNING - Using default Composer Environment Variables. Overrides have not been applied.
[2019-10-06 08:53:22,404] {base_task_runner.py:101} INFO - Job 15096: Subtask node-pool-test [2019-10-06 08:53:22,402] {configuration.py:522} INFO - Reading the config from /etc/airflow/airflow.cfg
[2019-10-06 08:53:22,424] {base_task_runner.py:101} INFO - Job 15096: Subtask node-pool-test [2019-10-06 08:53:22,423] {configuration.py:522} INFO - Reading the config from /etc/airflow/airflow.cfg
[2019-10-06 08:53:22,640] {base_task_runner.py:101} INFO - Job 15096: Subtask node-pool-test [2019-10-06 08:53:22,639] {models.py:273} INFO - Filling up the DagBag from /home/airflow/gcs/dags/dag_node_pool.py
[2019-10-06 08:53:23,816] {base_task_runner.py:101} INFO - Job 15096: Subtask node-pool-test [2019-10-06 08:53:23,815] {cli.py:520} INFO - Running <TaskInstance: dag_node_pool.node-pool-test 2019-10-06T08:51:02.859698+00:00 [running]> on host airflow-worker-69b68c899b-dgtw2
[2019-10-06 08:53:24,297] {base_task_runner.py:101} INFO - Job 15096: Subtask node-pool-test [2019-10-06 08:53:24,297] {pod_launcher.py:121} INFO - Event: node-pool-test-c14dd130 had an event of type Pending
[2019-10-06 08:53:25,310] {base_task_runner.py:101} INFO - Job 15096: Subtask node-pool-test [2019-10-06 08:53:25,310] {pod_launcher.py:121} INFO - Event: node-pool-test-c14dd130 had an event of type Pending
[2019-10-06 08:53:26,338] {base_task_runner.py:101} INFO - Job 15096: Subtask node-pool-test [2019-10-06 08:53:26,332] {pod_launcher.py:121} INFO - Event: node-pool-test-c14dd130 had an event of type Pending
...
[2019-10-06 08:54:26,076] {base_task_runner.py:101} INFO - Job 15096: Subtask node-pool-test [2019-10-06 08:54:26,073] {pod_launcher.py:121} INFO - Event: node-pool-test-c14dd130 had an event of type Succeeded
[2019-10-06 08:54:26,077] {base_task_runner.py:101} INFO - Job 15096: Subtask node-pool-test [2019-10-06 08:54:26,077] {pod_launcher.py:184} INFO - Event with job id node-pool-test-c14dd130 Succeeded
[2019-10-06 08:54:26,133] {base_task_runner.py:101} INFO - Job 15096: Subtask node-pool-test [2019-10-06 08:54:26,133] {pod_launcher.py:104} INFO - b'fakenerd\n'
[2019-10-06 08:54:26,150] {base_task_runner.py:101} INFO - Job 15096: Subtask node-pool-test [2019-10-06 08:54:26,149] {pod_launcher.py:121} INFO - Event: node-pool-test-c14dd130 had an event of type Succeeded
[2019-10-06 08:54:26,152] {base_task_runner.py:101} INFO - Job 15096: Subtask node-pool-test [2019-10-06 08:54:26,152] {pod_launcher.py:184} INFO - Event with job id node-pool-test-c14dd130 Succeeded
[2019-10-06 08:54:26,167] {base_task_runner.py:101} INFO - Job 15096: Subtask node-pool-test [2019-10-06 08:54:26,166] {pod_launcher.py:121} INFO - Event: node-pool-test-c14dd130 had an event of type Succeeded
[2019-10-06 08:54:26,171] {base_task_runner.py:101} INFO - Job 15096: Subtask node-pool-test [2019-10-06 08:54:26,169] {pod_launcher.py:184} INFO - Event with job id node-pool-test-c14dd130 Succeeded
[2019-10-06 08:54:26,562] {models.py:1641} ERROR - Received SIGTERM. Terminating subprocesses.
Workloads 탭에서도 DAG 의 Task 를 위해 실행된 Pod 내역을 볼 수 있습니다.
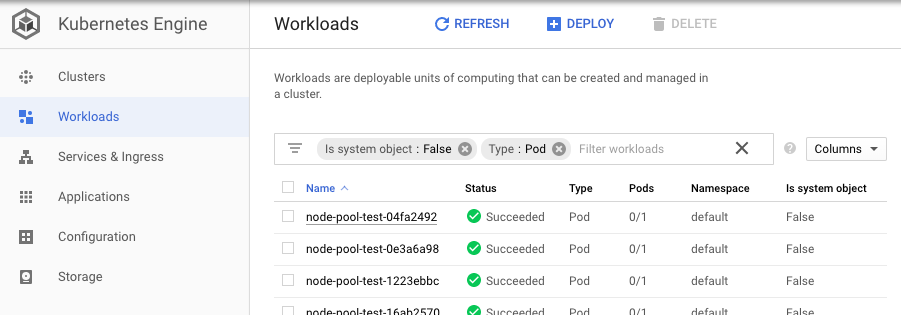
Autoscaling
앞서 Node Pool 생성 때 Number of nodes : 0 으로 설정했습니다. 그럼에도 Task 를 위한 Pod 이 정상적으로 실행될 수 있었던 것은, Node Pool 생성 때 Enable autoscaling 를 True 로 설정한 덕입니다. Cloud Shell 을 켜고 kubectl 명령어를 실행해서 관련 event 를 조회할 수 있습니다.
kubectl get events --all-namespaces --sort-by=.metadata.creationTimestamp | grep pool-1
kube-system 22m Warning FailedToScaleUpGroup ConfigMap Scale-up failed for group [...] timeout while waiting for operation [...] to complete.
default 21m Normal Scheduled Pod Successfully assigned default/node-pool-test-d3f0b47a to gke-us-central1-[...]
default 21m Normal NodeHasSufficientPID Node Node gke-us-central1-[...] status is now: NodeHasSufficientPID
default 21m Normal Scheduled Pod Successfully assigned default/node-pool-test-ccf2b560 to gke-us-central1-[...]
default 21m Normal NodeHasNoDiskPressure Node Node gke-us-central1-[...] status is now: NodeHasNoDiskPressure
default 21m Normal NodeHasSufficientMemory Node Node gke-us-central1-[...] status is now: NodeHasSufficientMemory
default 21m Normal NodeHasSufficientDisk Node Node gke-us-central1-[...] status is now: NodeHasSufficientDisk
default 21m Normal NodeReady Node Node gke-us-central1-[...] status is now: NodeReady
kube-system 21m Normal Scheduled Pod Successfully assigned kube-system/prometheus-to-sd-nthzz to gke-us-central1-[...]
default 21m Normal Scheduled Pod Successfully assigned default/node-pool-test-f07d934c to gke-us-central1-[...]
default 20m Normal Scheduled Pod Successfully assigned default/node-pool-test-1751eed2 to gke-us-central1-[...]
default 19m Normal Scheduled Pod Successfully assigned default/node-pool-test-36b4aada to gke-us-central1-[...]
kube-system 6m43s Normal ScaleDownEmpty ConfigMap Scale-down: removing empty node gke-us-central1-[...]
kube-system 6m37s Normal ScaleDownEmpty ConfigMap Scale-down: empty node gke-us-central1-[...] removed
크게 보면, DAG 의 Task 실행을 위한 Pod 요청 -> Node Group 의 size : 0 라서 Scale Up -> Pod Scheduling -> 요청된 Pod 완료 -> 일정 시간 (약 10분?) 동안 Node Group 에 대한 Pod 요청이 없으므로 Scale Down 이 발생하는 것으로 보입니다. 다만 맨 처음에 scale-up 이 실패했고, 이후 성공 event 가 없는데도 Scale Up 은 잘 됬다는 게 의아합니다. 이러한 Autoscaling 은 Cluster Autoscaler 가 담당하는데, 더 알아보고, 이를 주제로 후속 블로그 글을 작성할 계획입니다.
레퍼런스
- Cloud Composer 문서 중 Upgrading the machine type
- Cloud Composer 문서 중 Using the KubernetesPodOperator
- Kubernetes Engine 문서 중 Node pools
- Kubernetes Engine 문서 중 Cluster autoscaler
Cloud Composer 관련 다른 포스트
- Cloud Composer 시작하기
- Cloud Composer 를 업무에 처음 도입하며 정리한 몇가지 생각들
- Node Pool 로 KubernetesPodOperator 를 위한 독립된 실행 환경 구성하기
- Cloud Composer 에서 Airflow Web Server REST API 로 외부에서 DAG 트리거하기