google 의 Agents whitepaper 속 ReAct 에 대한 잡설
2025년은 ai agent 의 해가 될 거라는 전망들을 2024년 말에 많이 봤었다. 그리고 google 이 공개한 Agents whitepaper 에 대한 얘기들도 sns 에서 많이 봤었다. 그래서 읽어봤다.
40p 정도로 장수는 많았으나, 내용이 그리 많지 않아서 금방 읽었다. 사실 기대만큼 인상적인 내용은 아니었다. 옛날부터 있었던 chatgpt 의 function calling 과 뭐가 다른거지? 싶었다.
그나마 (개인적으로) 새로웠던 것은 ReAct 라는 개념이었다. 사실 그것도 2022년 10월 paper 로 오래 되었는데, 개인적으로는 이번에 처음 접했다.
whitepaper 에서 이 ReAct 얘기가 여러번 등장한다.
The model used by an agent can be one or multiple LM’s of any size (small / large) that are capable of following instruction based reasoning and logic frameworks, like
ReAct, Chain-of-Thought, or Tree-of-Thoughts.
ReAct, a prompt engineering framework that provides a thought process strategy for language models to Reason and take action on a user query, with or without in-context examples. ReAct prompting has shown to outperform several SOTA baselines and improve human interoperability and trustworthiness of LLMs.
For example, let’s consider an agent that is programmed to use the
ReActframework to choose the correct actions and tools for the user query. The sequence of events might go something like this:
In-context learning: This method provides a generalized model with a prompt, tools, and few-shot examples at inference time which allows it to learn ‘on the fly’ how and when to use those tools for a specific task. The
ReActframework is an example of this approach in natural language.
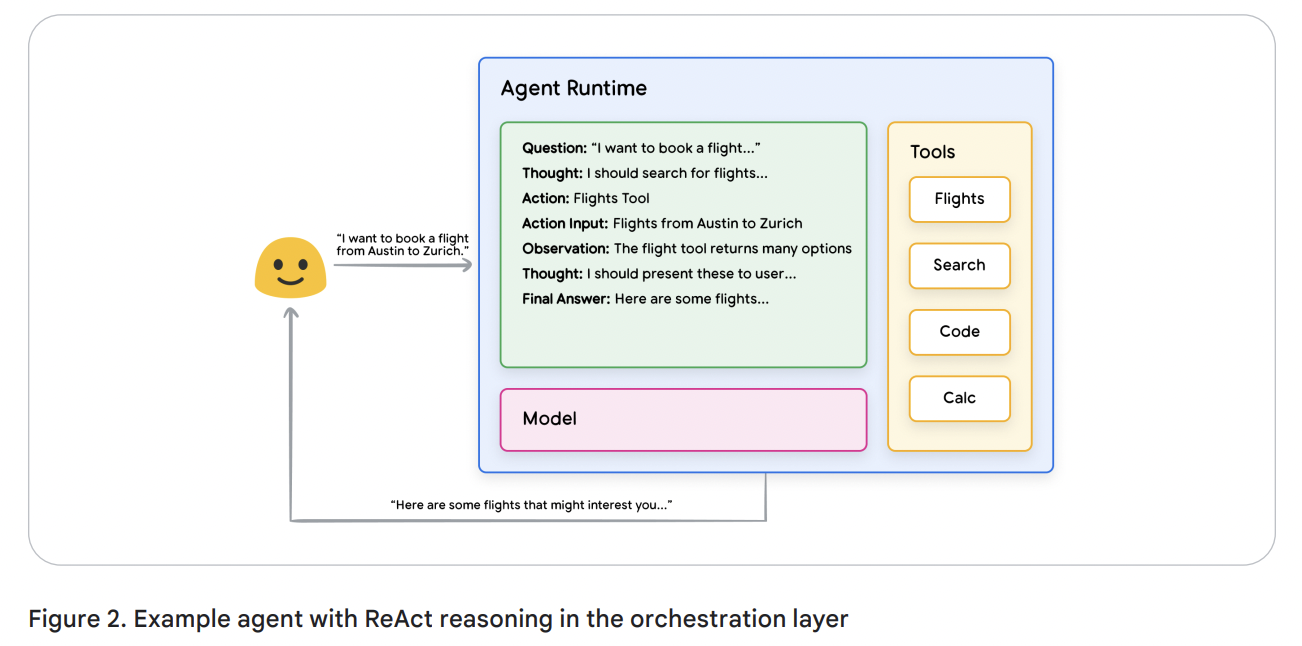
At the heart of an agent’s operation is the orchestration layer, a cognitive architecture that structures reasoning, planning, decision-making and guides its actions. Various reasoning techniques such as
ReAct, Chain-of-Thought, and Tree-of-Thoughts, provide a framework for the orchestration layer to take in information, perform internal reasoning, and generate informed decisions or responses.
Reason 과 Action 을 반복한다고 하여 ReAct 인가보다.
The sequence of events might go something like this:
- User sends query to the agent
- Agent begins the ReAct sequence
- The agent provides a prompt to the model, asking it to generate one of the next ReAct steps and its corresponding output:
Question: The input question from the user query, provided with the promptThought: The model’s thoughts about what it should do nextAction: The model’s decision on what action to take next
- This is where tool choice can occur
- For example, an action could be one of [Flights, Search, Code, None], where the first 3 represent a known tool that the model can choose, and the last represents “no tool choice”
Action input: The model’s decision on what inputs to provide to the tool (if any)Observation: The result of the action / action input sequence
- This thought / action / action input / observation could repeat N-times as needed
Final answer: The model’s final answer to provide to the original user query
example code 를 보면 langgraph 에서 create_react_agent 를 제공하고, langchain 에서 tool 들을 제공한다.
import os
from langchain_community.utilities import SerpAPIWrapper
from langchain_core.tools import tool
from langchain_google_community import GooglePlacesTool
from langchain_google_vertexai import ChatVertexAI
from langgraph.prebuilt import create_react_agent
# https://serpapi.com/dashboard
os.environ["SERPAPI_API_KEY"] = "..."
# https://developers.google.com/maps/documentation/places/web-service/get-api-key#console
os.environ["GPLACES_API_KEY"] = "..."
@tool
def search(query: str):
"""Use the SerpAPI to run a Google Search."""
serp_api_wrapper = SerpAPIWrapper()
return serp_api_wrapper.run(query)
@tool
def places(query: str):
"""Use the Google Places API to run a Google Places Query."""
google_places_tool = GooglePlacesTool()
return google_places_tool.run(query)
model = ChatVertexAI(model="gemini-1.5-flash-001", project="...")
tools = [search, places]
query = "Who did the Texas Longhorns play in football last week? What is the address of the other team's stadium?"
agent = create_react_agent(model, tools)
input_ = {"messages": [("human", query)]}
for s in agent.stream(input_, stream_mode="values"):
message = s["messages"][-1]
if isinstance(message, tuple):
print(message)
else:
message.pretty_print()
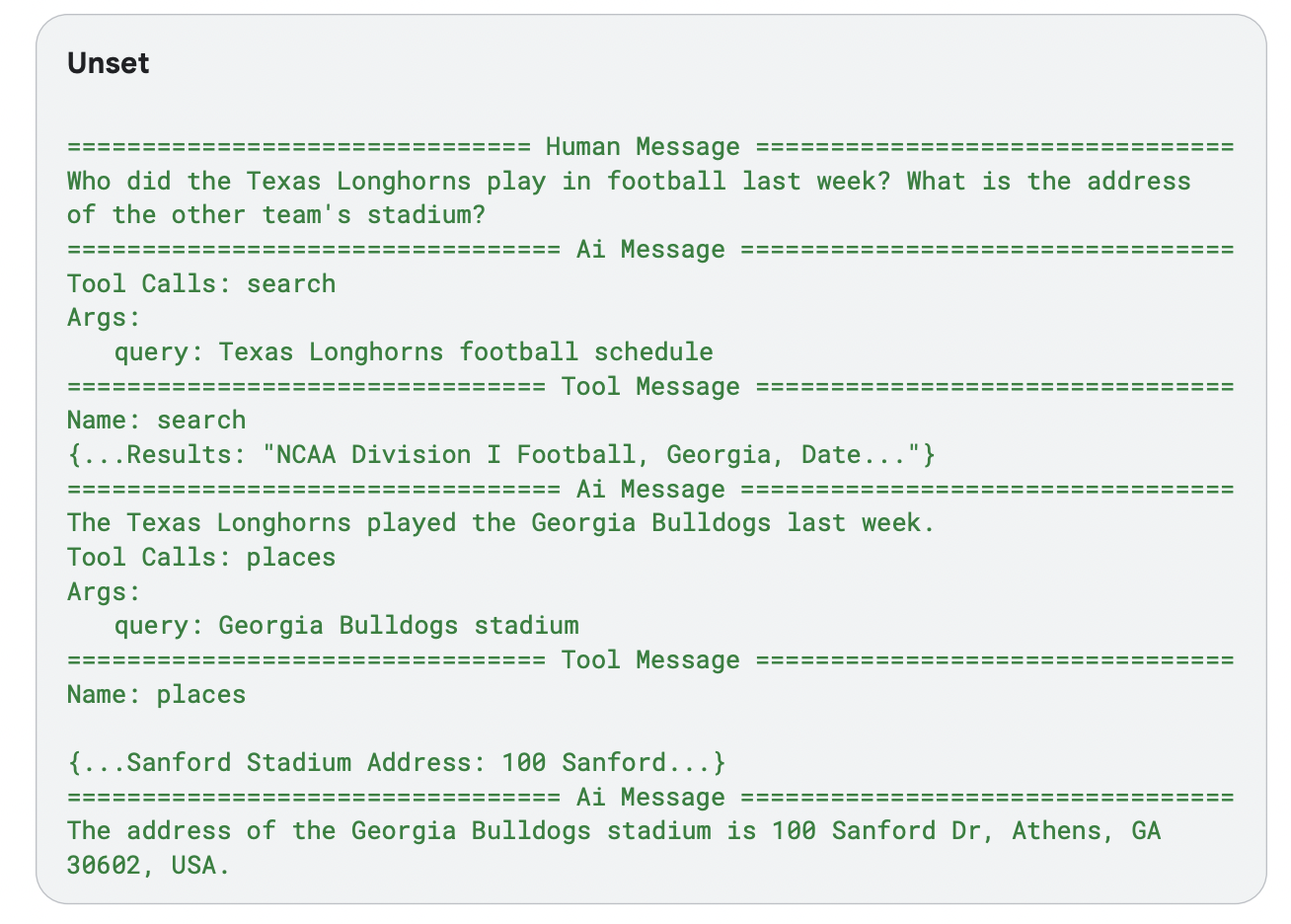
절차적 -> 선언적 으로의 shift 로 보인다. 목표를 달성하기 위해, llm 을 여러번 호출하고, 그 일련의 호출 들을 결합 해야하는 경우가 빈번하다. 그 결합을 직접 rule-based 의 code 로 작성하는 대신, 단위 작업들만 tool 로 선언하고, 결합은 orchestrator 에게 맡기는 것.
그런데 오늘 날에는 llm provider 들이 자체적으로 o3, deep research 같은 강력한 reasoning 을 제공 한다. 그렇게 o3-mini 에도 function calling 이 제공되는 현 시점에, 직접 create_react_agent 를 호출 하거나 langgraph 에서 graph 를 선언 하고 build 하게 될 일이 있을까?